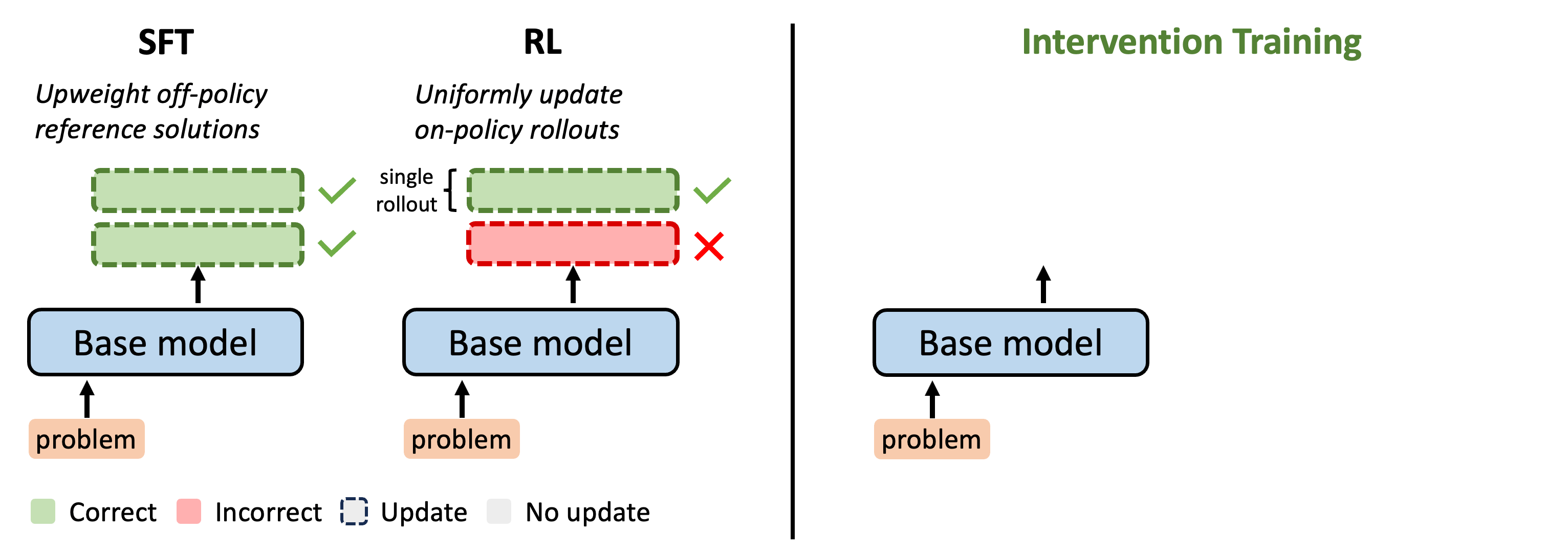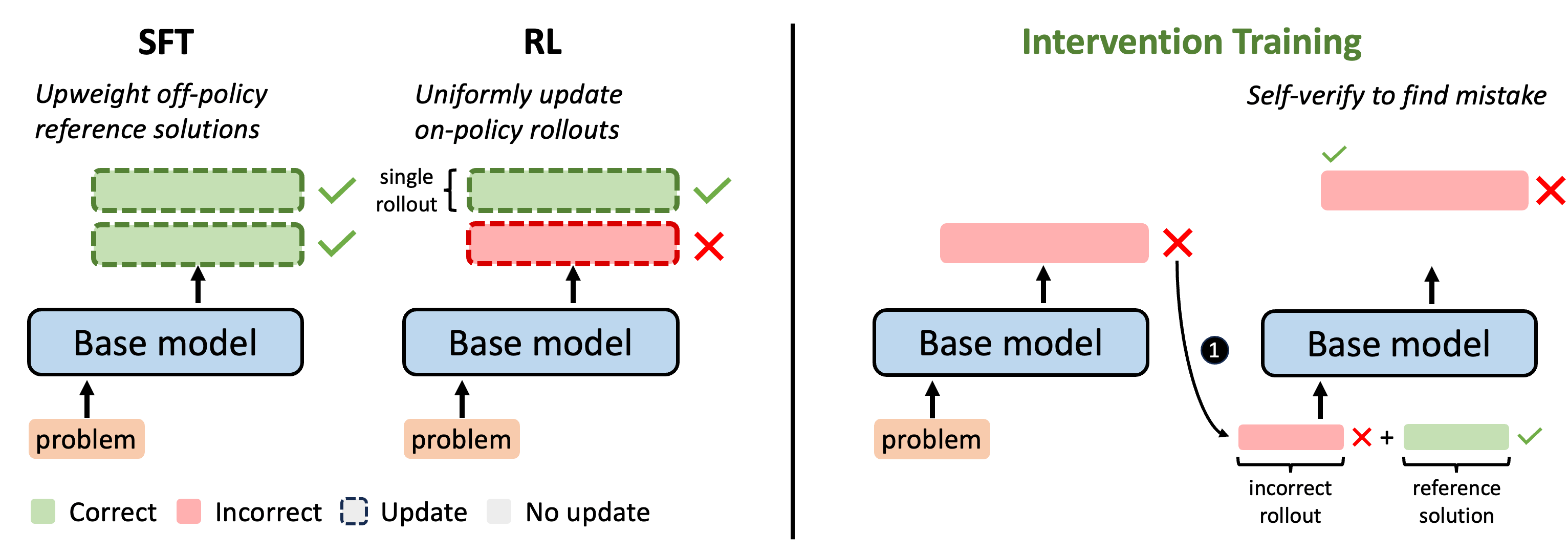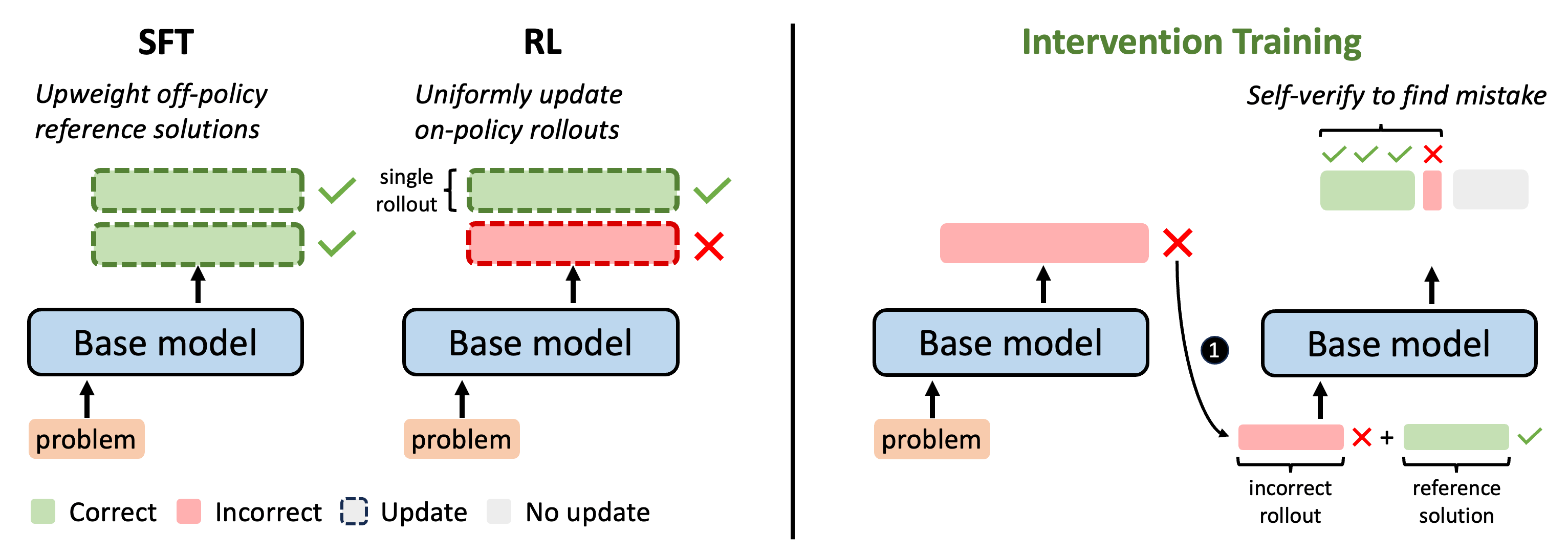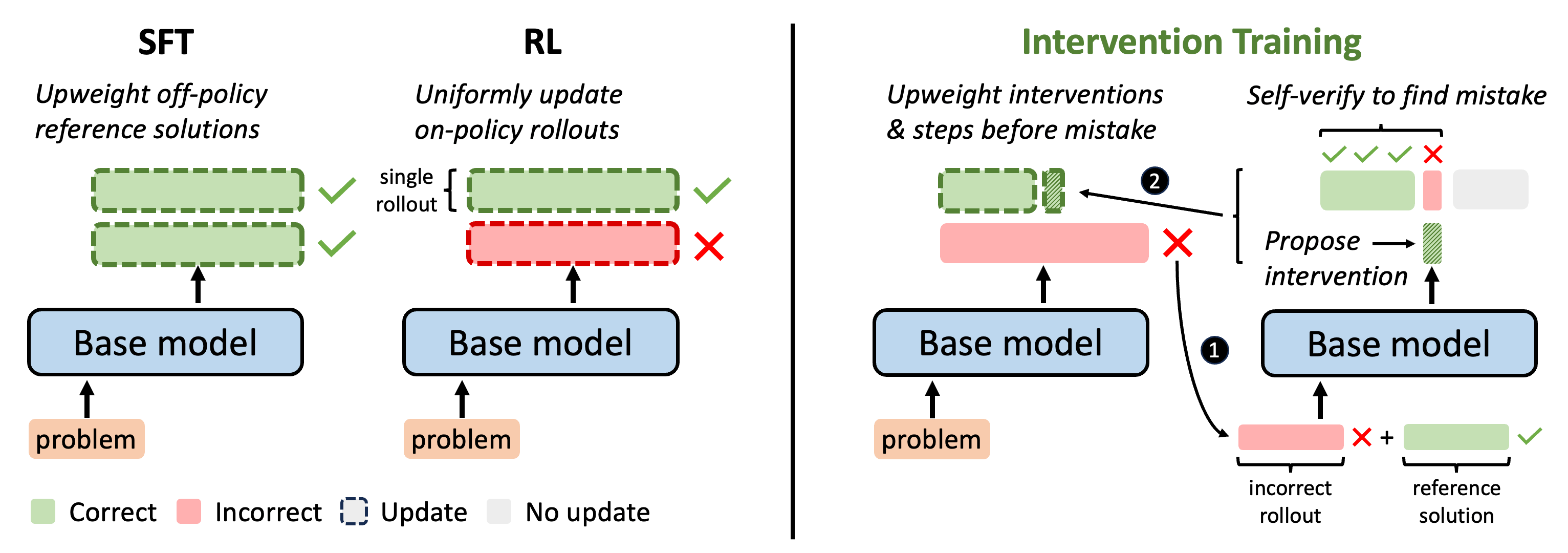
Outcome-reward reinforcement learning (RL) has proven effective at improving the reasoning capabilities of large language models (LLMs). However, standard RL assigns credit only at the level of the final answer, penalizing entire reasoning traces when the outcome is incorrect and uniformly reinforcing all steps when it is correct. As a result, correct intermediate steps may be discouraged in failed traces, while spurious steps may be reinforced in successful ones. We refer to this failure mode as the problem of credit assignment. While a natural remedy is to train a process reward model, accurately optimizing such models to identify corrective reasoning steps remains challenging. We introduce Intervention Training (InT), a training paradigm in which the model performs fine-grained credit assignment on its own reasoning traces by proposing short, targeted corrections that steer trajectories toward higher reward. Using reference solutions commonly available in mathematical reasoning datasets and exploiting the fact that verifying a model-generated solution is easier than generating a correct one from scratch, the model identifies the first error in its reasoning and proposes a single-step intervention to redirect the trajectory toward the correct solution. We then apply supervised fine-tuning (SFT) to the on-policy rollout up to the point of error concatenated with the intervention, localizing error to the specific step that caused failure. We show that the resulting model serves as a far better initialization for RL training. After running InT and subsequent fine-tuning with RL, we improve accuracy by nearly 14% over a 4B-parameter base model on IMO-AnswerBench, outperforming larger open-source models such as gpt-oss-20b.
Upon receiving zero reward, outcome-based RL methods like GRPO cannot pinpoint which specific reasoning steps led to the incorrect final answer. Instead, it downweights the entire trajectory. What we really want is to identify the exact locations of mistakes and penalize only those steps. How can we do this without expensive rollouts or training PRMs? In this work, we leverage the strong verification abilities of LLMs to construct a more informative learning signal.
In our method, we correct an incorrect rollout by intervening at the exact point of error. We do the following:
| Rollouts Are Conditioned On | Coverage | Accuracy |
|---|---|---|
| problem x + correct prefix y<t* + original step yt* | 29 / 334 | 0.0713% |
| problem x + correct prefix y<t* + intervention ỹt* | 80 / 334 | 1.56% |
As shown above, continuing from the interventions rather from the original erroneous step leads to much better accuracy and coverage, measured as pass@32. We also provide two examples of interventions here:

After obtaining the interventions, we perform SFT on them and then apply downstream RL.
We compare SFT on interventions against performing SFT on other forms of data. They include:
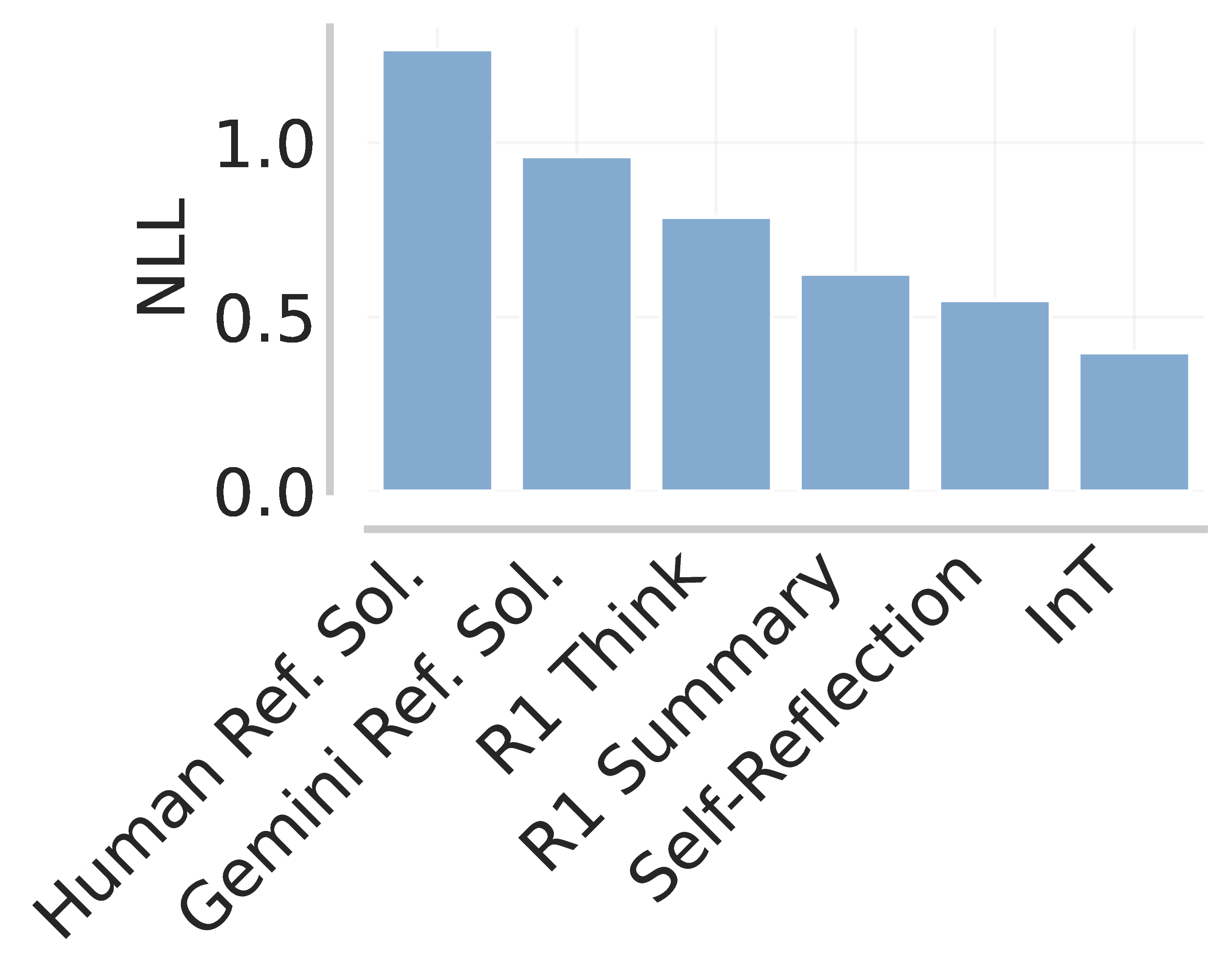
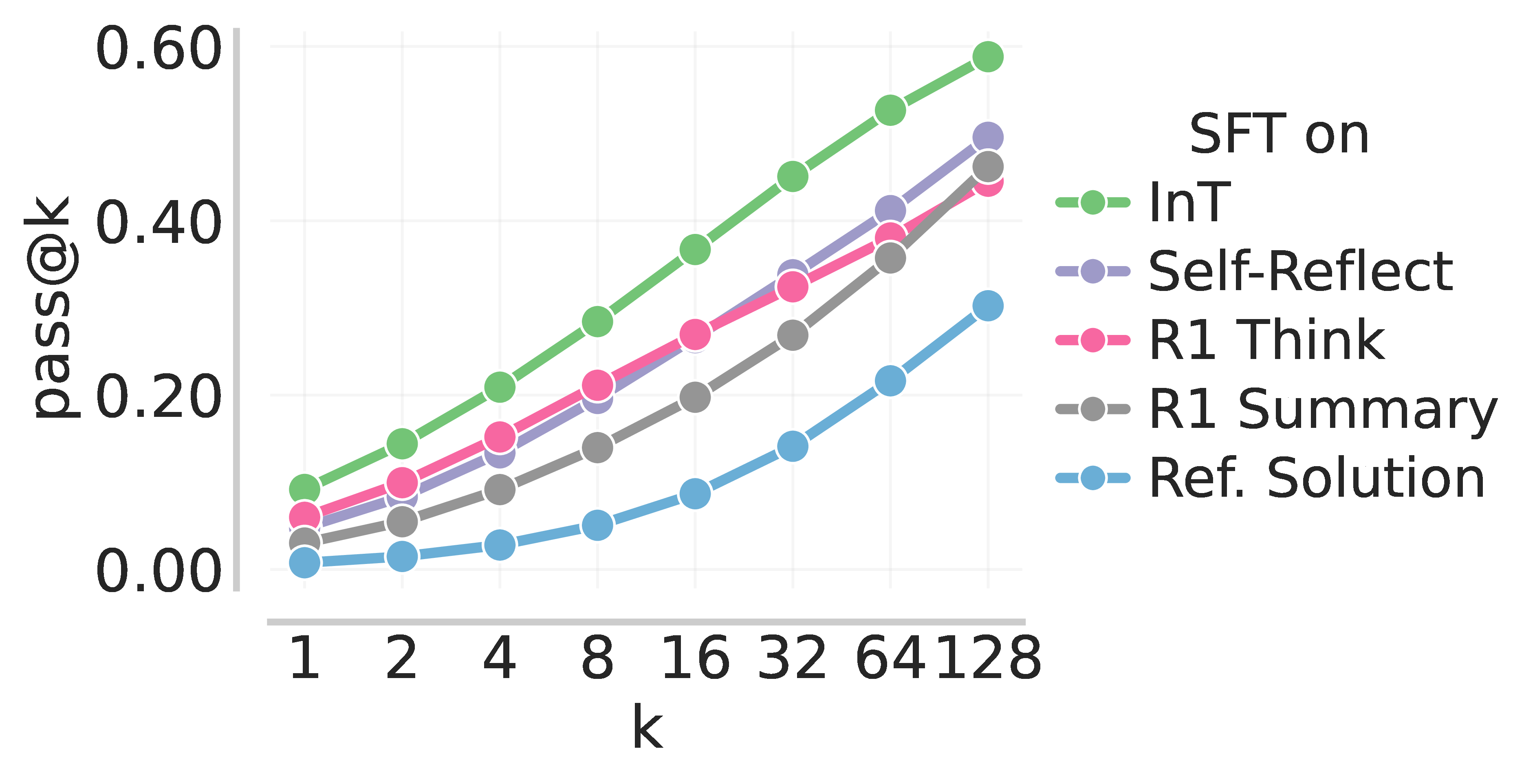
(left) Average negative log-likelihood (NLL) computed over 64 sampled traces. (middle) Train pass@k on 64 sampled training problems. InT achieves the highest pass@k. (right) Test pass@𝑘 on IMO-Bench, AMO-Bench, and Apex Shortlist. InT again attains the best pass@k.
As shown above, we observe a correlation between the "on-policiness" (i.e., likelihood under base model) of SFT data and the post-SFT performance. InT traces are the most on-policy, and lead to the best performance, whereas reference solutions are the least on-policy, and consistently lead to the worst performance.
So InT leads to the highest post-SFT pass@k, and therefore provides a good initialization for online RL to reinforce the learned interventions. We find that RL on the InT checkpoint yields higher reward and lower zero advantage ratio (defined as the fraction of problems for which the model never produces a correct rollout) when compared to the other baselines.
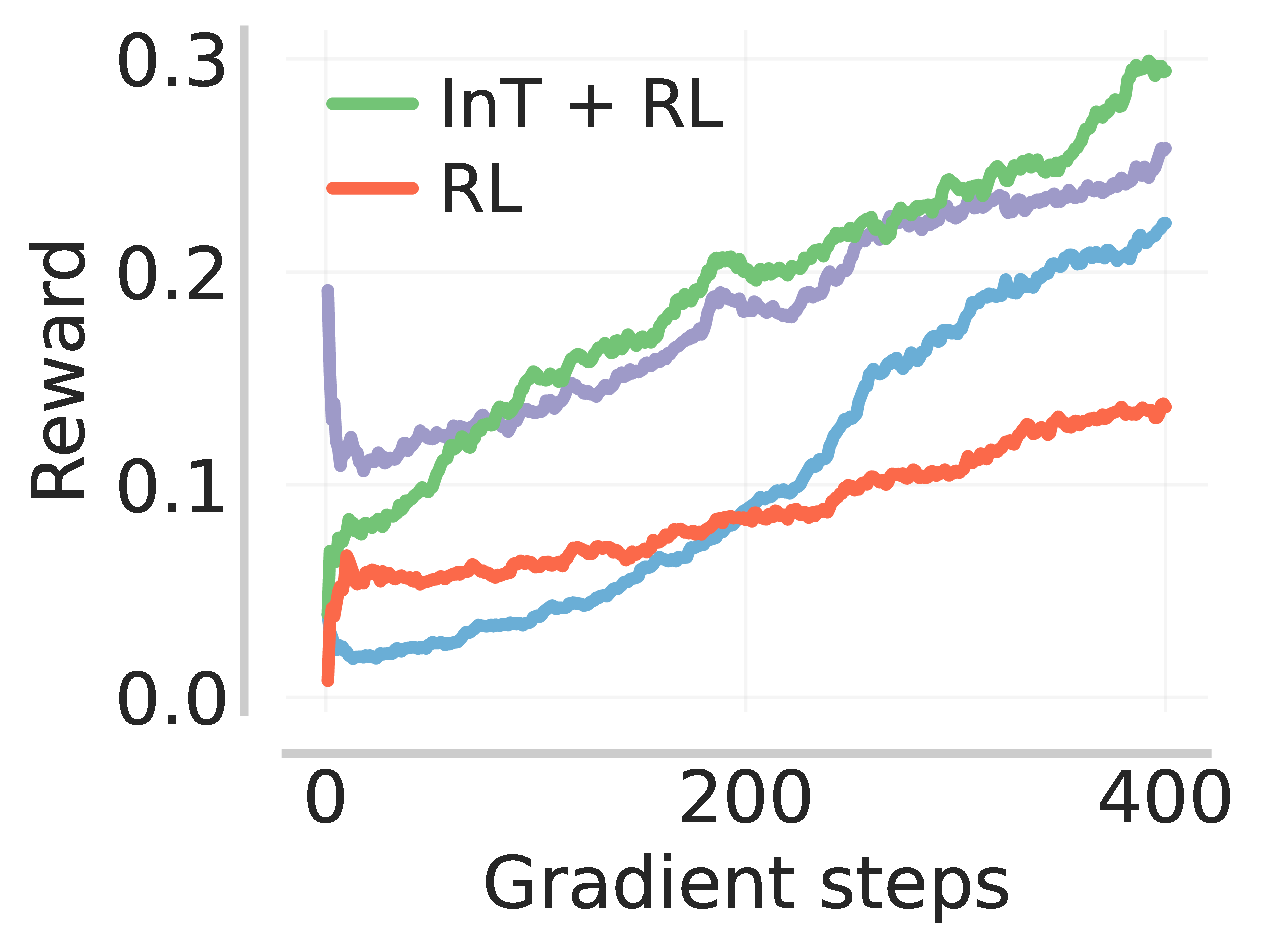
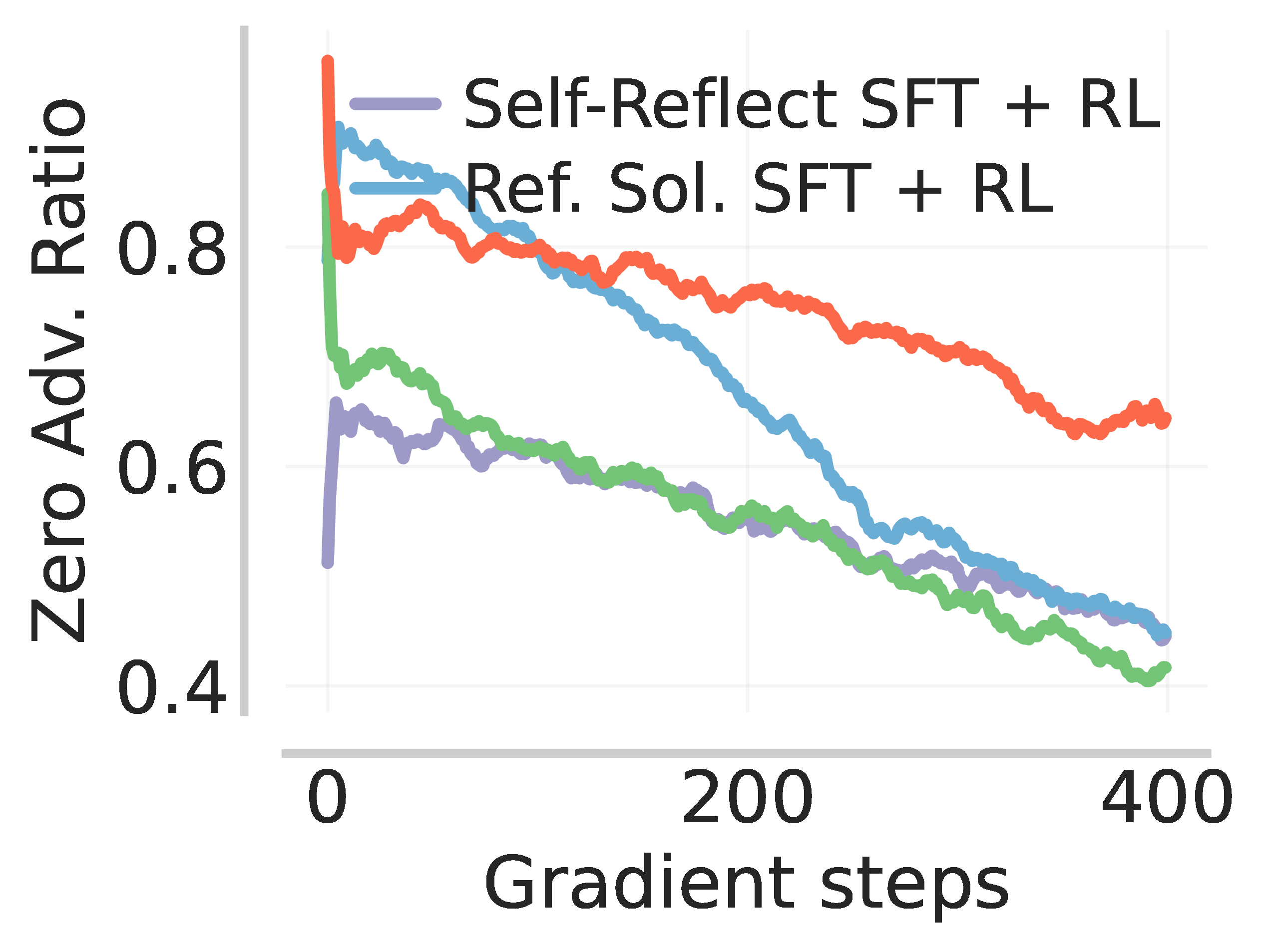
In the table below, we report the downstream RL performance on several benchmarks, evaluated at 16K tokens. Notably, initializing RL with InT leads to a near 14% improvement on IMO-Answerbench, beating larger models such as DeepSeek-R1-0528-Qwen3-8B (18.44%) and gpt-oss-20b (23.36%) evaluated at a larger budget of 32K.
| Model | IMO-AnswerBench | HMMT 2025 Nov | AMO-Bench pass@8 | Apex Shortlist pass@8 | Dtrain | Average |
|---|---|---|---|---|---|---|
| Base | 11.68 | 41.61 | 26.24 | 20.79 | 5.53 | 21.17 |
| + RL | 23.46 | 46.46 | 35.21 | 22.72 | 13.47 | 28.26 |
| + SFT on ref. solutions + RL | 11.56 | 27.45 | 25.19 | 20.51 | 19.07 | 20.76 |
| + InT + RL (Ours) | 25.62 | 49.77 | 36.16 | 28.22 | 28.83 | 33.72 |